




在音频处理领域,人声提取技术已成为音乐制作、影视后期、播客制作及会议记录整理的核心需求。随着算法优化与工具迭代,用户可通过专业软件、在线平台或AI工具实现高效分离。录音怎么提取人声?本文将从技术原理、工具选择及操作流程三方面展开分析。
一、技术原理与核心挑战
人声提取的核心在于通过频谱分析、机器学习或信号处理技术分离目标声源与背景音。传统方法依赖频谱减法或Wiener滤波,通过识别并消除噪声频段实现降噪,但易导致语音失真。现代AI技术如深度神经网络(DNN)通过训练海量音频数据,可更精准识别人声特征。例如,Spleeter、UVR5等开源工具已实现人声与伴奏的自动化分离,但复杂混音场景仍需人工干预。
二、主流工具分类与实操指南
1. 专业音频编辑软件
Adobe Audition:支持频谱编辑与多轨降噪,用户可通过“频谱分析”面板手动绘制人声频段,适合复杂混音场景。
Audacity:开源免费工具,提供“降噪”与“人声增强”插件,操作流程为:导入音频→获取噪声样本→调整参数→导出人声,适合非专业用户。
2. 在线AI平台
易我人声分离:支持噪音消除与人声分离,适合处理会议录音等环境噪声复杂的场景。用户上传文件后,AI自动生成人声与噪音轨道。
录音怎么提取人声?详细的操作步骤如下:
步骤1.访问并登录易我人声分离官网页面,选择“人声分离”功能。
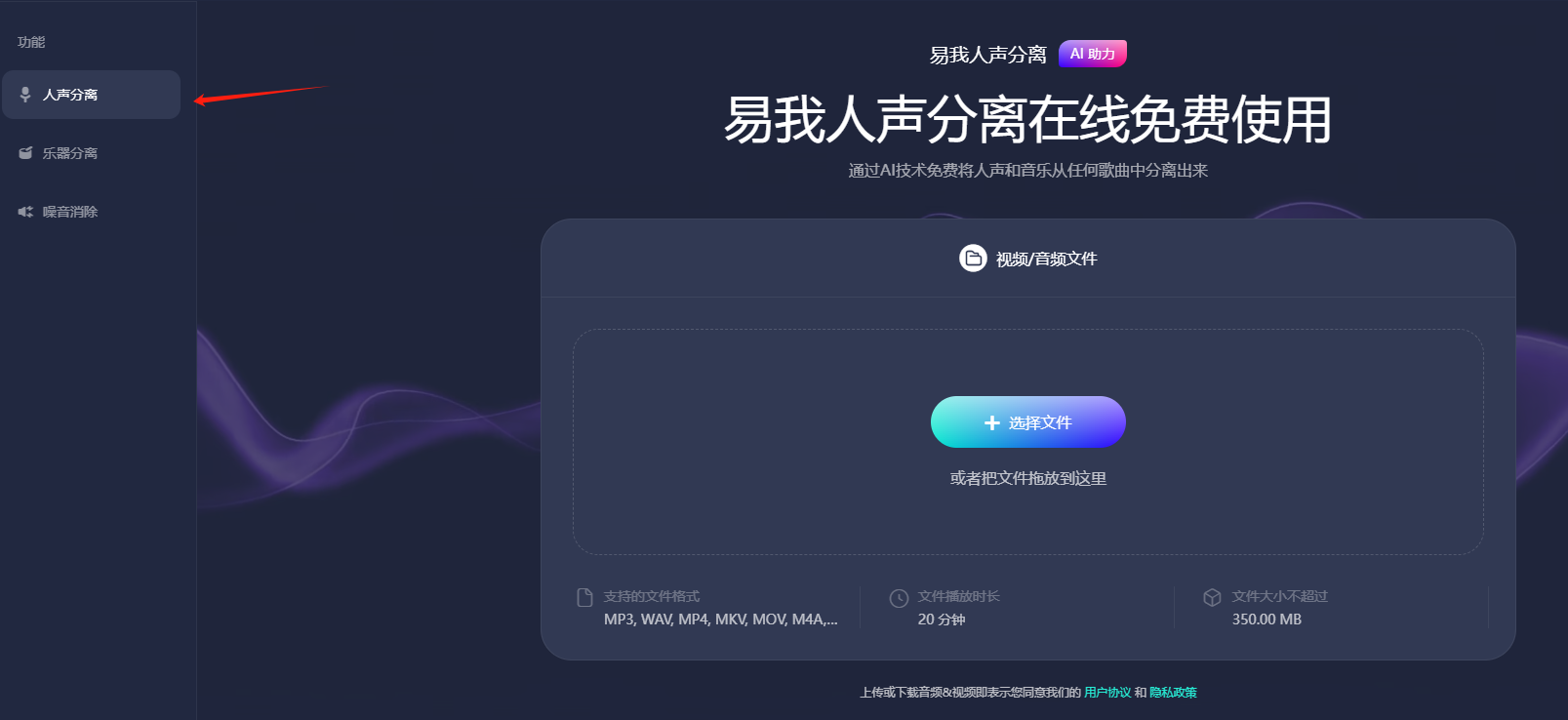
步骤2.点击“选择文件”,把音频或者视频文件上传到网页窗口中(或者直接拖拽文件到窗口中),等待AI处理。


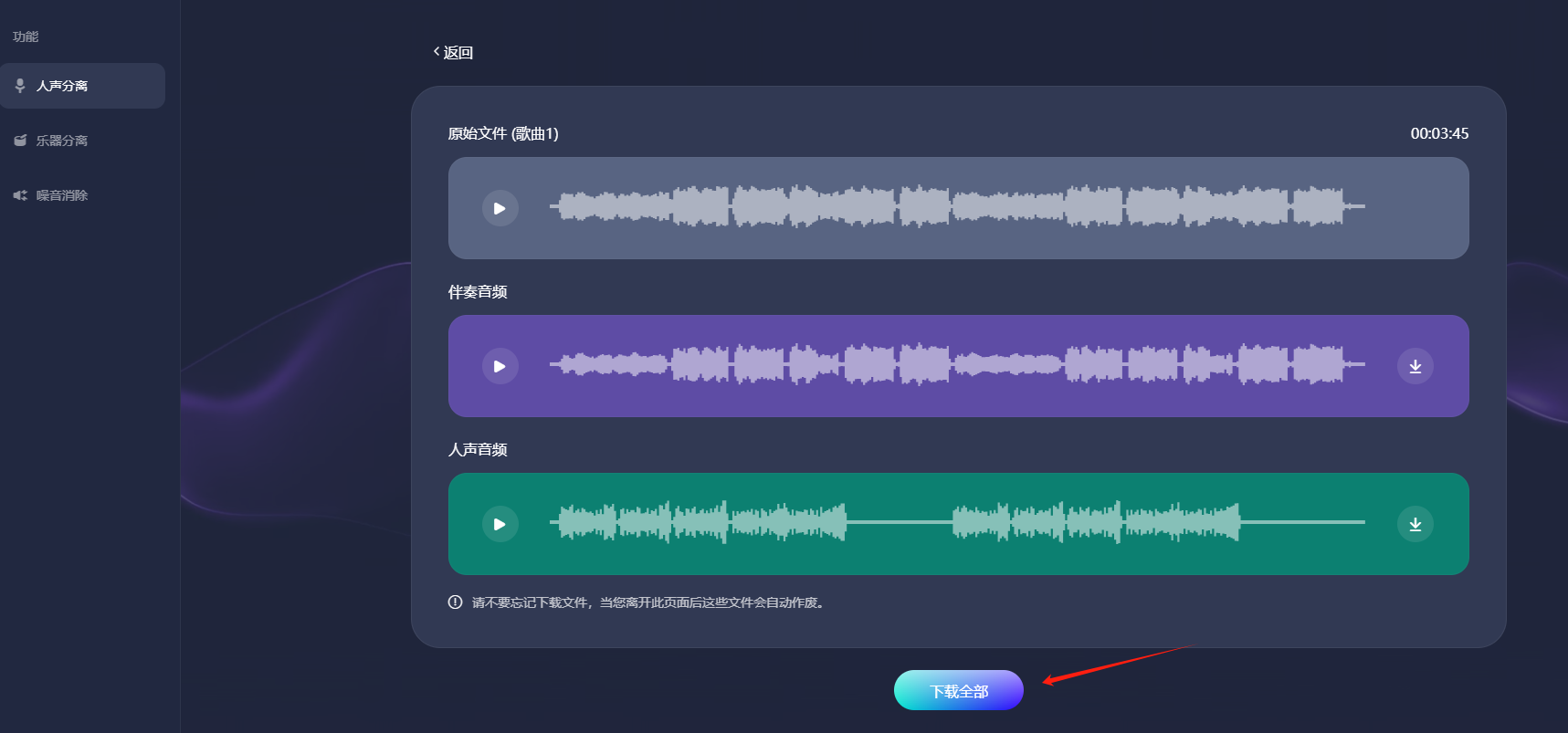
步骤3.AI处理完成后,会生成伴奏音频和人声音频,点击“下载全部”即可把音频下载到您的电脑上。
注意:请不要忘记下载文件,当您离开此页面后这些文件会自动作废。
三、进阶技巧与注意事项
降噪与分离的协同优化
在复杂录音中,需先通过Audacity的“降噪”功能或Adobe Audition的“自适应降噪”插件消除环境噪声,再提取人声。例如,处理课堂录音时,可先消除空调、风扇等低频噪声,再分离人声与背景音乐。
多轨分离与后期调整
对于音乐作品,建议使用易我人声分离这样支持多轨道分离的工具,将人声、鼓、贝斯等分轨处理。分离后可通过均衡器(EQ)调整中高频段(如2-5kHz)以增强人声清晰度,或通过压缩器控制动态范围。
文件格式与质量选择
导出时建议选择无损格式(如WAV)以保留音质,若需压缩则选择高比特率MP3(如320kbps)。在线平台通常限制文件大小(如70MB),处理大文件时可分段上传或使用本地软件。
四、应用场景与案例分析
音乐制作:制作人可分离人声与伴奏,重新混音或制作Remix版本。
影视后期:消除现场录音中的环境噪声,再提取对白进行字幕同步。
播客制作:分离背景音乐,确保人声清晰度。
会议记录:消除键盘敲击声与空调噪声,生成纯净语音文本。
结语
录音怎么提取人声?人声提取技术已从专业领域走向大众化,用户可根据需求选择工具:初学者推荐Audacity或易我人声分离,专业用户可选用Adobe Audition。未来,随着实时处理与跨平台协作能力提升,人声提取将进一步降低音频制作门槛,助力内容创作者高效产出优质作品。

 怎么把音频里面的说话声和音乐分开?人声分离工具推荐
怎么把音频里面的说话声和音乐分开?人声分离工具推荐

 歌曲天路伴奏提取全攻略,收藏不迷路!
歌曲天路伴奏提取全攻略,收藏不迷路!
 珊瑚颂的歌曲纯伴奏怎么提取?有效的提伴奏技巧
珊瑚颂的歌曲纯伴奏怎么提取?有效的提伴奏技巧
 音频里的背景音乐和人声能分离吗?从技术原理到方法讲解
音频里的背景音乐和人声能分离吗?从技术原理到方法讲解
 音频去掉背景杂音,照着教程做,三步轻松去杂音!
这个人声分离的软件,在线就能解锁纯净声场
音频去掉背景杂音,照着教程做,三步轻松去杂音!
这个人声分离的软件,在线就能解锁纯净声场
 视频去除噪音不降低人声如何同时实现?收藏本教程立刻掌握!
手机录音有杂音怎么处理?巧用易我人声分离高效去杂音
视频去除噪音不降低人声如何同时实现?收藏本教程立刻掌握!
手机录音有杂音怎么处理?巧用易我人声分离高效去杂音
 怎么把视频的声音提取成MP3?三个方法轻松提声音
新手友好向:长江之歌伴奏MP3原版的提取制作教程
怎么把视频的声音提取成MP3?三个方法轻松提声音
新手友好向:长江之歌伴奏MP3原版的提取制作教程
 苹果手机录音怎么去除杂音?从环境优化到后期降噪
苹果手机录音怎么去除杂音?从环境优化到后期降噪
 电脑提取视频中的音频要怎么做?新手教程来了
电脑提取视频中的音频要怎么做?新手教程来了