




在视频制作中,背景噪音(如风声、电流声、环境嘈杂声)常干扰人声清晰度,影响观众体验。传统降噪方法易导致人声失真,而现代技术通过智能算法实现了“精准降噪,人声无损”的目标。视频去除噪音不降低人声如何同时实现?本文将从技术原理、工具选择到实操步骤,系统解析如何实现这一目标。
一、技术原理:区分噪音与人声的底层逻辑
1、频谱分析技术
通过快速傅里叶变换(FFT)将音频分解为不同频率成分,识别噪音(如低频嗡嗡声、高频嘶嘶声)与人声的频率分布差异。人声通常集中在200Hz-4kHz的中高频段,而噪音可能分布更广或集中于特定频段。
2、基于深度学习的降噪算法
通过海量音频数据训练,能够自动学习噪音特征模式,并区分动态变化的人声与背景噪音。
3、多通道相位处理
在立体声或多声道音频中,通过比较不同声道的相位差异,可定位并保留人声方向的声音,同时削弱其他方向的噪音。
二、工具选择:专业软件与AI工具
专业音频编辑软件:以Adobe Audition、Audacity为代表,能实现精细控制参数,支持多轨编辑,适合影视后期、播客制作等场景。
AI工具:以易我人声分离为代表,支持一键降噪,保留人声细节实现无损音质,无需安装,适合快速处理音视频的场景。
三、视频去除噪音不降低人声:以易我人声分离为例
步骤1.访问并登录易我人声分离官网页面,选择“人声分离”功能。
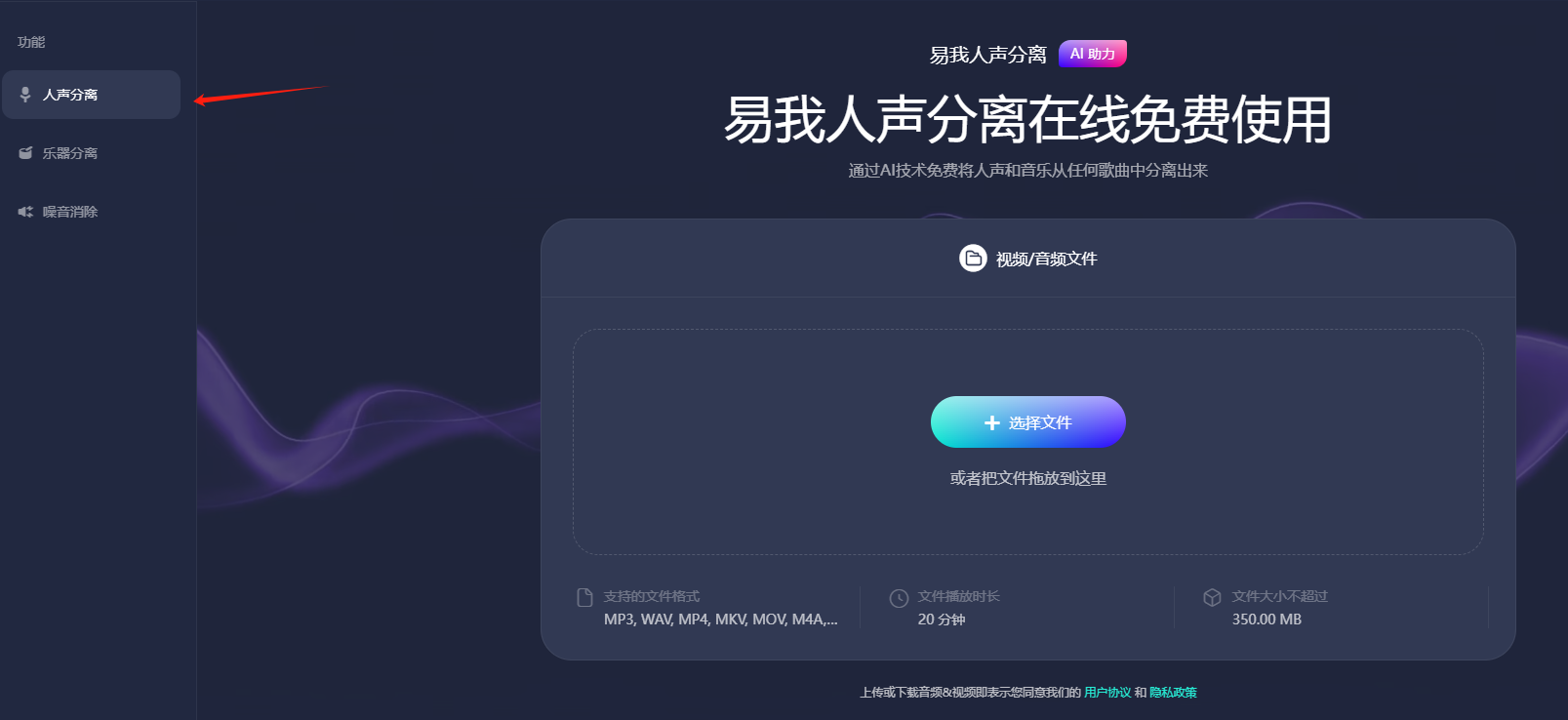
步骤2.点击“选择文件”,把音频或者视频文件上传到网页窗口中(或者直接拖拽文件到窗口中),等待AI处理。


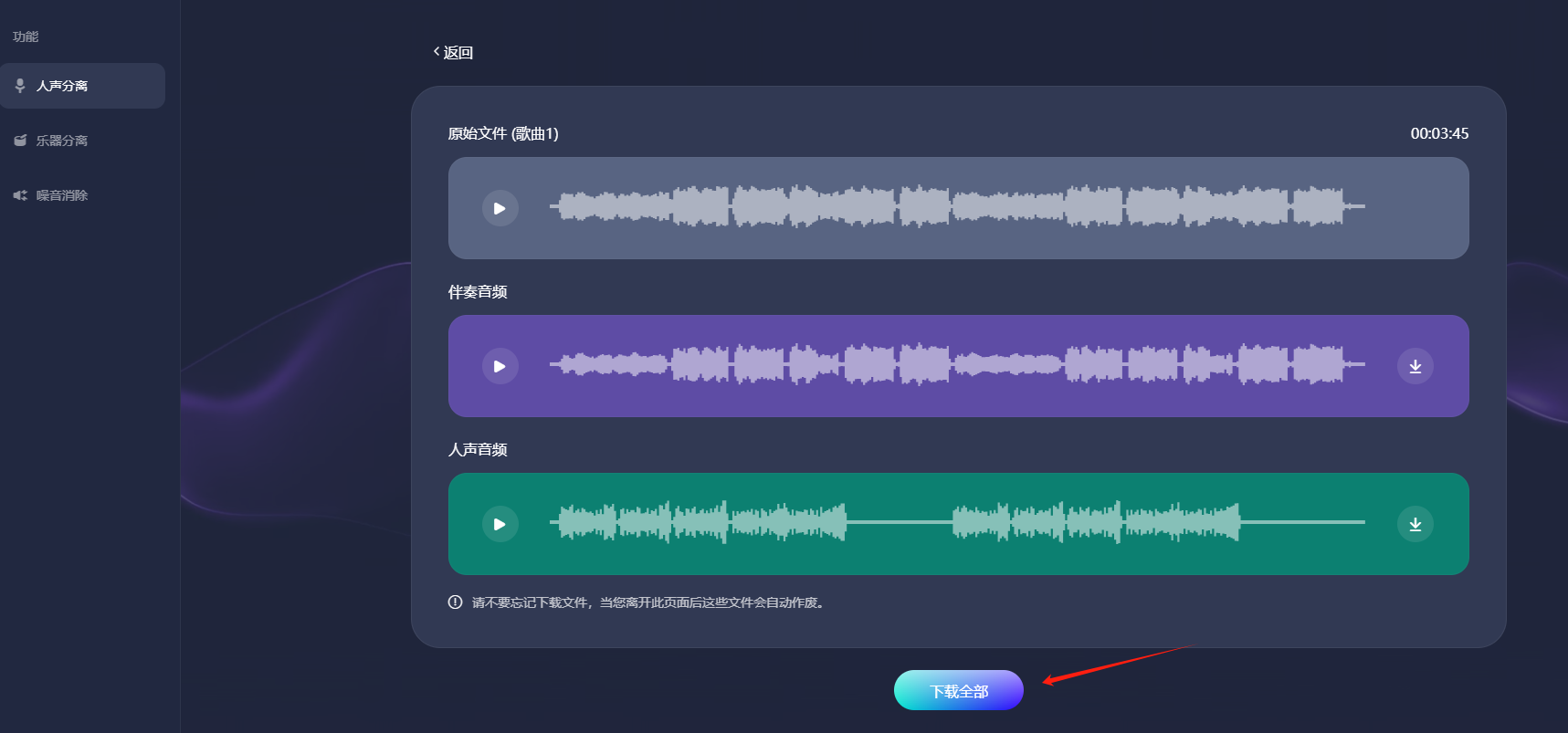
步骤3.AI处理完成后,会生成伴奏音频和人声音频,点击“下载全部”即可把音频下载到您的电脑上。
注意:请不要忘记下载文件,当您离开此页面后这些文件会自动作废。
四、常见误区与避坑指南
误区1:过度依赖降噪量
降噪量超过60%易引发“水下声”效应,建议分多次轻度降噪。
误区2:忽视环境适应性
户外风声需用防风罩+低切滤波器(如120Hz以下切除),而非单纯降噪。
误区3:未备份原始文件
降噪处理不可逆,务必保留原始音频以便后续调整。
五、结语
视频去除噪音不降低人声,本质是信号处理的“减法艺术”。通过理解技术原理、选择合适的工具,并结合场景化调整,创作者可在不妥协音质的前提下,打造清晰纯净的音频体验。未来,随着AI技术的深化,降噪将更智能、更无感,让内容创作回归创意本身。

 手机录音有杂音怎么处理?巧用易我人声分离高效去杂音
手机录音有杂音怎么处理?巧用易我人声分离高效去杂音

 怎么把视频的声音提取成MP3?三个方法轻松提声音
怎么把视频的声音提取成MP3?三个方法轻松提声音
 新手友好向:长江之歌伴奏MP3原版的提取制作教程
新手友好向:长江之歌伴奏MP3原版的提取制作教程
 苹果手机录音怎么去除杂音?从环境优化到后期降噪
苹果手机录音怎么去除杂音?从环境优化到后期降噪
 电脑提取视频中的音频要怎么做?新手教程来了
电脑提取视频中的音频要怎么做?新手教程来了
 音频提取人声分离技术:原理与具体实践
音频提取人声分离技术:原理与具体实践
 长歌行背景音乐如何从视频中单独提取?四个提取教程
长歌行背景音乐如何从视频中单独提取?四个提取教程
 如何将视频中的音乐提取出来保存?三个方法都能提取
如何将视频中的音乐提取出来保存?三个方法都能提取
 这个提取人声网站,只需要上传音乐就能实现人声分离!
这个提取人声网站,只需要上传音乐就能实现人声分离!
 如何提取音乐中的人声?简单有效的方法推荐
如何提取音乐中的人声?简单有效的方法推荐
 从人声中剥离伴奏,女儿情歌曲伴奏的提取技巧
从人声中剥离伴奏,女儿情歌曲伴奏的提取技巧
 这个人声分离AI工具,可一键提取歌曲伴奏!
这个人声分离AI工具,可一键提取歌曲伴奏!