




在数字化音频处理领域,人声分离是一项旨在从混合音频中提取人声或伴奏的技术。无论是音乐制作、影视后期还是语音识别预处理,这一技术都能显著提升音频处理的灵活性与效率。本文将系统梳理音频提取人声分离技术的核心方法。
一、传统信号处理方法:基于物理特性的分离策略
在传统音频工程中,人声分离主要依赖声学特征与统计模型的结合,典型方法包括:
1、频谱减法(Spectral Subtraction)
通过估计背景噪声的频谱特性,从混合信号中减去噪声成分。该方法假设人声与伴奏在频域上具有可分性,但对信噪比敏感,易引入音乐噪声。
2、谐波/打击乐分离(HPSS)
利用人声(谐波成分为主)与打击乐(瞬态成分为主)的频谱差异,通过中值滤波分离两类信号。该方法在伴奏含明显鼓点时效果突出,但对复杂编曲的泛化能力不足。
3、非负矩阵分解(NMF)
将音频频谱分解为基矩阵与激活矩阵的乘积,通过训练特定乐器/人声的基向量实现分离。该方法需要高质量的训练数据,且对相位信息丢失敏感。
二、深度学习方法:数据驱动的端到端革命
随着深度学习的兴起,基于神经网络的方法逐渐成为主流,其优势在于:
1、监督学习框架
使用MUSDB18等标准数据集训练模型,直接学习混合信号到目标人声/伴奏的映射。典型网络结构包括:
U-Net变体:如Spleeter采用编码器-解码器架构,通过跳跃连接保留高频细节。
时频域联合处理:Demucs模型在时域波形与频域谱图间建立双路径,提升相位重建精度。
2、自监督学习突破
最近研究提出MixIT框架,通过随机混合多源音频并重建各成分,无需干净标签即可训练分离模型,显著降低数据标注成本。
3、领域自适应技术
针对实际音频与训练数据的域偏移问题,采用对抗训练(如CycleGAN)或特征对齐方法,提升模型在真实场景中的鲁棒性。
三、音频提取人声分离的实践
现如今有多种从音频肿提取人声的技术,其中,AI人声分离技术以其易用性和分离成果的高质量而走进大众的视线。
易我人声分离就是这样一款依靠AI人工智能算法,能一键分离人声与伴奏的实用工具。
步骤1.访问并登录易我人声分离官网页面,选择“人声分离”功能。
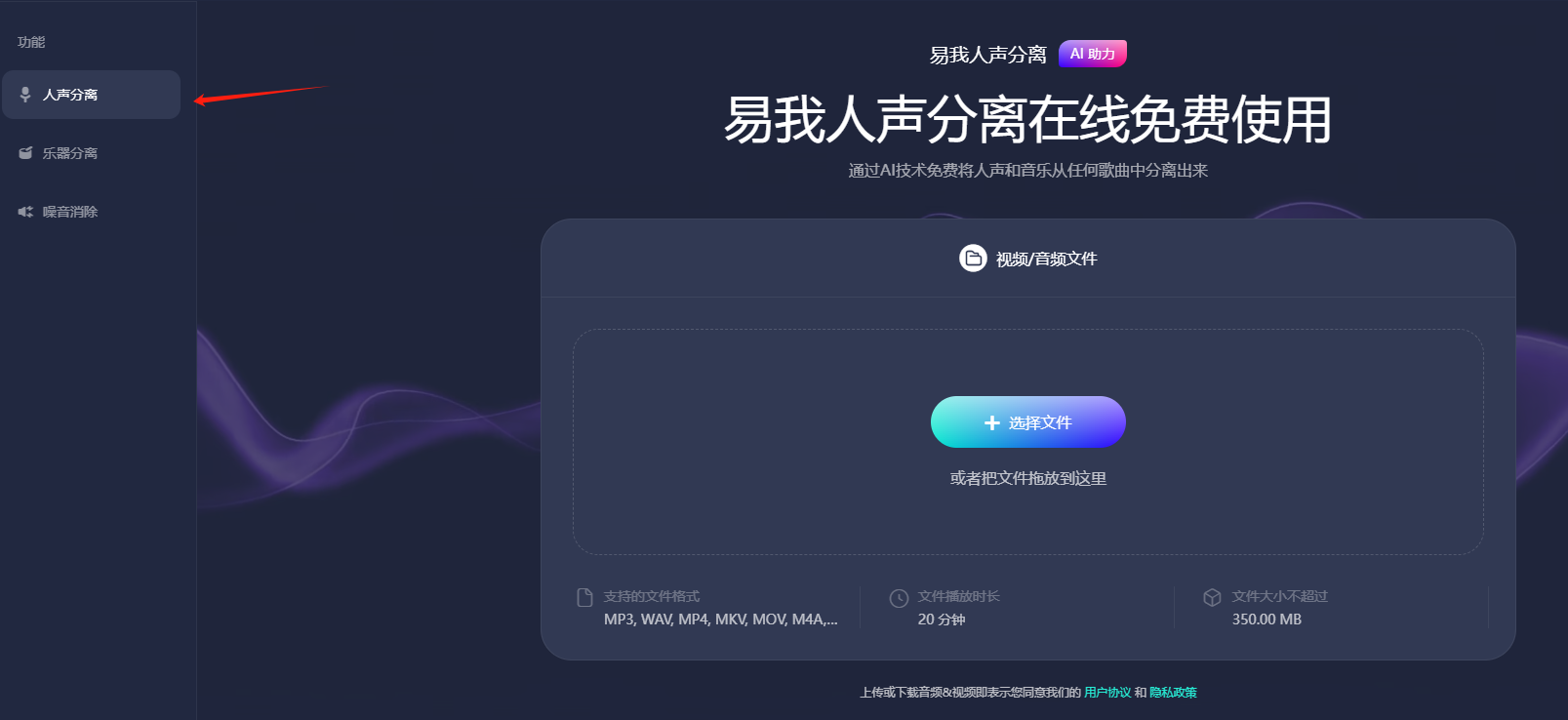
步骤2.点击“选择文件”,把音频或者视频文件上传到网页窗口中(或者直接拖拽文件到窗口中),等待AI处理。


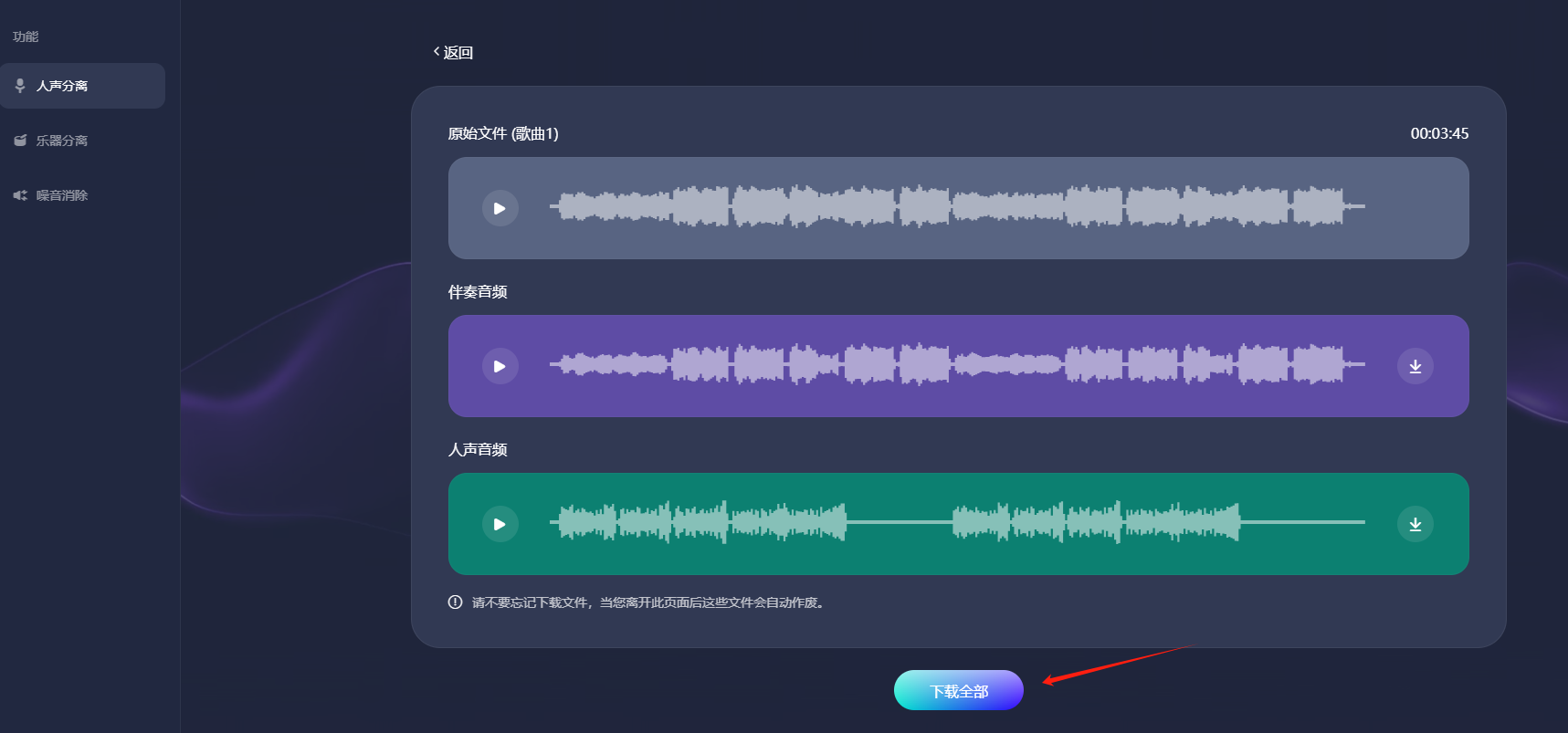
步骤3.AI处理完成后,会生成伴奏音频和人声音频,点击“下载全部”即可把音频下载到您的电脑上。
注意:请不要忘记下载文件,当您离开此页面后这些文件会自动作废。
四、总结
音频提取人声分离技术正从学术研究走向规模化应用,其核心价值在于将音频处理从"手动调参"时代带入"智能解析"阶段。未来随着神经声学模型的发展,我们有望看到更细粒度(如情感表达分离)、更自适应(如根据歌词内容优化分离策略)的音频智能系统诞生,进一步释放音频数据的潜在价值。

 长歌行背景音乐如何从视频中单独提取?四个提取教程
长歌行背景音乐如何从视频中单独提取?四个提取教程

 如何将视频中的音乐提取出来保存?三个方法都能提取
如何将视频中的音乐提取出来保存?三个方法都能提取
 这个提取人声网站,只需要上传音乐就能实现人声分离!
这个提取人声网站,只需要上传音乐就能实现人声分离!
 如何提取音乐中的人声?简单有效的方法推荐
如何提取音乐中的人声?简单有效的方法推荐
 从人声中剥离伴奏,女儿情歌曲伴奏的提取技巧
从人声中剥离伴奏,女儿情歌曲伴奏的提取技巧
 这个人声分离AI工具,可一键提取歌曲伴奏!
这个人声分离AI工具,可一键提取歌曲伴奏!
 录音底噪怎么消除?去除录音噪音的全方位步骤
录音底噪怎么消除?去除录音噪音的全方位步骤
 怎么分离 背景音乐和人声?这些办法轻松实现!
怎么分离 背景音乐和人声?这些办法轻松实现!
 手机录音噪音大如何消除杂音?总结了六招
手机录音噪音大如何消除杂音?总结了六招
 怎么把录音的噪音去掉?从这两个教程入手
怎么把录音的噪音去掉?从这两个教程入手
 音频人声分离在线工具,在网页上就能提取歌曲伴奏
提取视频中音频的软件!电脑软件与小程序推荐
音频人声分离在线工具,在网页上就能提取歌曲伴奏
提取视频中音频的软件!电脑软件与小程序推荐