




易我人声分离
在音频处理领域,怎么把音频里面的说话声和音乐分开?传统方法依赖人工调参或基础滤波技术,但效果有限。随着人工智能技术的突破,深度学习算法为音频分离提供了更高效、精准的解决方案。
一、技术原理:深度学习驱动的智能分离
音频分离的核心在于利用算法模型识别并分离混合信号中的不同声源。传统方法(如频谱编辑、中置声道提取)依赖人工调整参数,存在以下局限:
频谱编辑法:需手动调整频段音量,操作复杂且对复杂音频效果不佳;
中置声道提取法:基于立体声相位特性,但人声与乐器可能混杂,分离纯净度不足。
AI技术的引入彻底改变了这一局面。基于深度学习的分离模型(如U-Net、Demucs)通过大量数据训练,能够自动学习人声与乐器的频谱特征、谐波结构等差异,实现更高精度的分离。
二、人声分离工具推荐
易我人声分离是一个支持在线使用的AI音频处理工具,它适合快速分离的场景,无需安装,支持MP3、WAV等主流格式;操作简单是需要“上传音频→AI自动处理→下载分离结果”这三个步骤即可完成。
三、怎么把音频里面的说话声和音乐分开
以下以易我人声分离为例,演示在线分离的完整流程:
步骤1.访问并登录易我人声分离官网页面,选择“人声分离”功能。
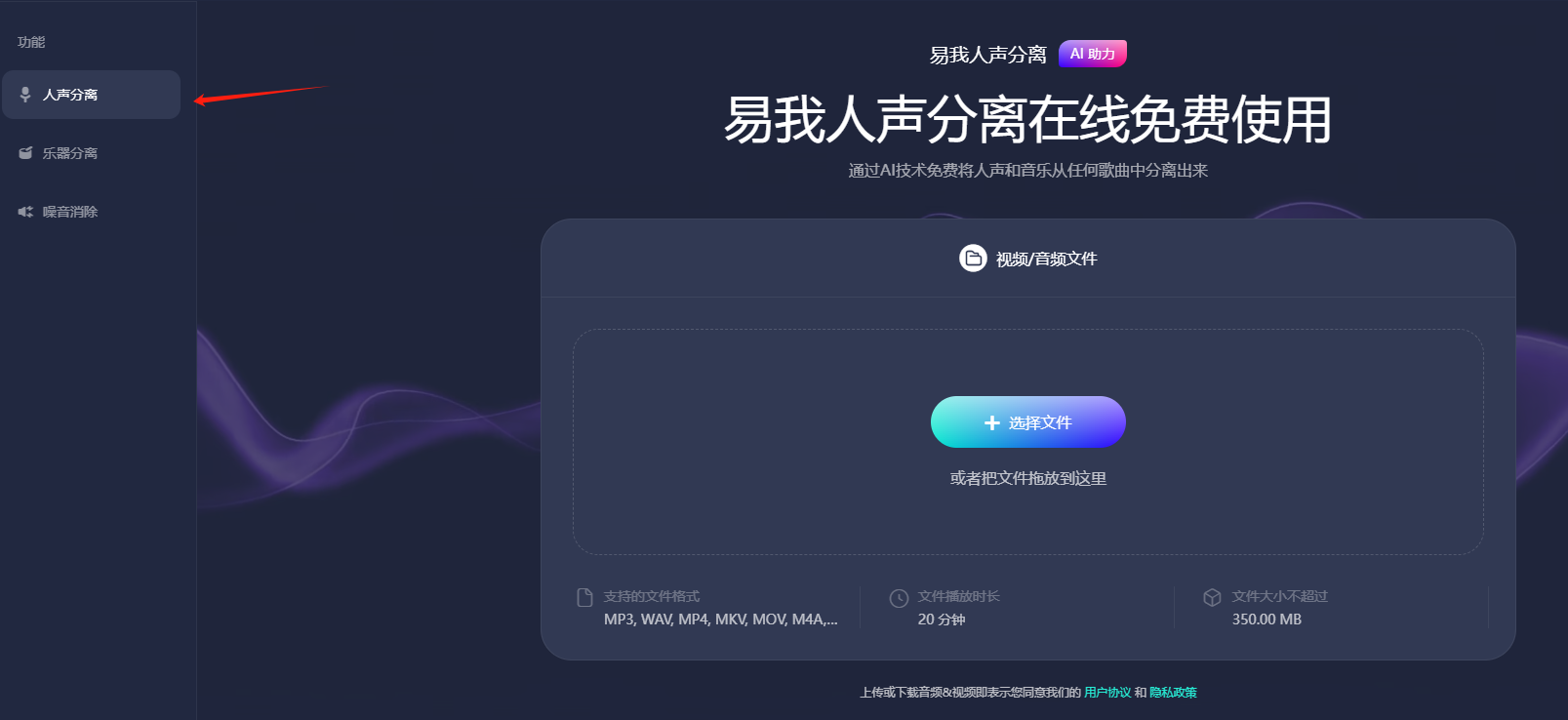
步骤2.点击“选择文件”,把音频或者视频文件上传到网页窗口中(或者直接拖拽文件到窗口中),等待AI处理。


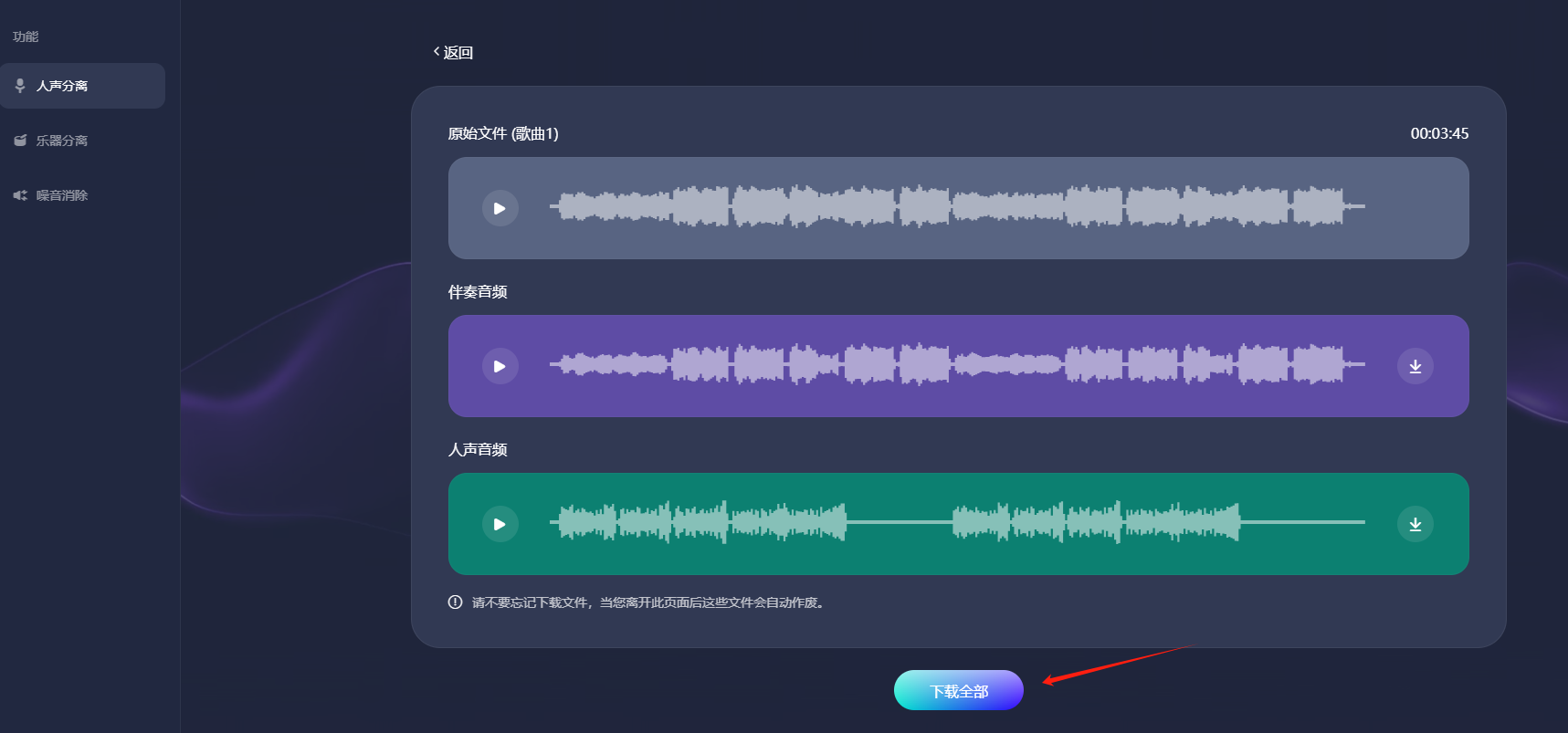
步骤3.AI处理完成后,会生成伴奏音频和人声音频,点击“下载全部”即可把音频下载到您的电脑上。
注意:请不要忘记下载文件,当您离开此页面后这些文件会自动作废。
四、结语
怎么把音频里面的说话声和音乐分开?无论是音乐制作、影视后期,还是语音识别,音频分离技术正为内容创作与处理带来革命性变革。通过选择合适的工具,用户可根据需求灵活应对不同场景。未来,随着AI技术的进一步成熟,音频分离将变得更加智能、高效,为创意产业注入更多可能性。
猜你想看

 歌曲天路伴奏提取全攻略,收藏不迷路!
歌曲天路伴奏提取全攻略,收藏不迷路!
在音乐创作、翻唱录制或舞蹈编排中,获取《天路》这类经典歌曲的高品质伴奏是关键需求。由于原曲中藏族长调与交响乐的复杂编曲,传统相位消除法易导致高频乐器失真,需结合AI算法与专业工具实现精准分离。本文从技术原理、工具选择到实战操作,系统解析歌曲天路伴奏提取方案。一、技术挑战与核心原理《天路》的编曲特点对伴奏提取提出三大挑战:频段重叠:藏语念白(200Hz-3kHz)与弦乐泛音(1.5-8kHz)存在频

513
2025-04-25 15:41
 珊瑚颂的歌曲纯伴奏怎么提取?有效的提伴奏技巧
珊瑚颂的歌曲纯伴奏怎么提取?有效的提伴奏技巧
在音乐制作、视频剪辑或是个人娱乐中,我们常常需要提取歌曲的纯伴奏版本,以便进行二次创作或作为背景音乐使用。以经典红歌《珊瑚颂》为例,珊瑚颂的歌曲纯伴奏怎么提取?本文将探讨如何有效提取其纯伴奏,介绍几种常见的方法及其操作步骤。一、利用专业音频编辑软件Adobe Audition是一款功能强大的音频编辑软件,支持多轨编辑和高级音频处理功能,是提取纯伴奏的常用工具之一。珊瑚颂的歌曲纯伴奏提取步骤如下:导
476
2025-04-24 16:08
 音频里的背景音乐和人声能分离吗?从技术原理到方法讲解
音频里的背景音乐和人声能分离吗?从技术原理到方法讲解
在数字音频处理领域,一个常见而颇具挑战性的问题是:音频里的背景音乐和人声能分离吗?随着人工智能和信号处理技术的飞速发展,音频分离技术正逐步从实验室走向实际应用,为这一难题提供了创新的解决方案。一、音频里的背景音乐和人声能分离吗?技术原理1. 基于物理特性的传统方法早期,音频分离主要依赖于音频信号的物理特性,如频率、相位和时域差异。例如,通过滤波器技术,可以尝试根据人声与乐器声在频谱上的不同分布进行
841
2025-04-24 15:50
 音频去掉背景杂音,照着教程做,三步轻松去杂音!
音频去掉背景杂音,照着教程做,三步轻松去杂音!
在音频处理领域,音频去掉背景杂音一直是困扰创作者、播客、视频制作者以及音乐爱好者的难题。无论是录制环境不佳导致的噪音,还是设备本身产生的电流声,这些杂音都会严重影响音频质量,让听众体验大打折扣。如果你正为如何去除音频中的背景杂音而烦恼,不妨试试易我人声分离这款专业工具,只需三步,就能轻松实现纯净人声的提取与背景噪音的彻底消除!一、为什么选择易我人声分离?易我人声分离是一款基于先进AI技术的音频处理
586
2025-04-23 13:58
这个人声分离的软件,在线就能解锁纯净声场
在音频处理领域,人声与背景音乐的分离一直是创作者、视频剪辑师及音乐爱好者的核心需求。无论是制作卡拉OK伴奏、提取影视对话、清理嘈杂录音,还是进行二次创作,精准高效的人声分离的软件都至关重要。然而,传统软件常因安装繁琐、操作复杂或收费高昂让人望而却步。今天,一款名为易我人声分离的在线工具正以其“无需下载、一键处理”的革新体验,重新定义音频处理的便捷性。一、轻量便捷:告别下载,云端即开即用作为一款人声
984
2025-04-18 15:34
 视频去除噪音不降低人声如何同时实现?收藏本教程立刻掌握!
视频去除噪音不降低人声如何同时实现?收藏本教程立刻掌握!
在视频制作中,背景噪音(如风声、电流声、环境嘈杂声)常干扰人声清晰度,影响观众体验。传统降噪方法易导致人声失真,而现代技术通过智能算法实现了“精准降噪,人声无损”的目标。视频去除噪音不降低人声如何同时实现?本文将从技术原理、工具选择到实操步骤,系统解析如何实现这一目标。一、技术原理:区分噪音与人声的底层逻辑1、频谱分析技术通过快速傅里叶变换(FFT)将音频分解为不同频率成分,识别噪音(如低频嗡嗡声
619
2025-04-14 13:52
手机录音有杂音怎么处理?巧用易我人声分离高效去杂音
在数字化时代,手机录音已成为记录灵感、会议内容或创作素材的便捷工具。然而,环境噪音、设备限制或操作不当常导致录音中混入杂音,影响听感与可用性。手机录音有杂音怎么处理?本文将系统解析杂音成因,并重点介绍如何通过易我人声分离软件高效去除杂音,同时提供辅助优化方案,助您轻松获得清晰纯净的音频。一、手机录音杂音成因分析1、环境干扰背景噪音(如风声、交通声、人群嘈杂)直接混入录音。录音时手机与声源距离过远,
1053
2025-04-10 13:33
 怎么把视频的声音提取成MP3?三个方法轻松提声音
怎么把视频的声音提取成MP3?三个方法轻松提声音
在日常生活中,我们经常会遇到需要从视频中提取音频的情况,比如将电影中的经典对白、音乐视频中的旋律等保存为MP3格式,以便在移动设备上随时播放。那么,怎么把视频的声音提取成MP3格式呢?以下是几种简单且实用的方法。方法一:使用专业格式转换软件工具推荐:易我视频转换器。操作步骤:导入视频文件:打开易我视频转换器,选择“音频提取”功能,然后导入需要提取音频的视频文件。设置输出格式:在输出格式中选择“MP
658
2025-04-07 13:30
 新手友好向:长江之歌伴奏MP3原版的提取制作教程
新手友好向:长江之歌伴奏MP3原版的提取制作教程
《长江之歌》是一首脍炙人口的歌曲,其激昂的旋律和深情的歌词深受人们喜爱。有时候,我们可能希望提取出这首歌的伴奏部分,用于练习演唱、音乐创作或其他用途。本文将介绍几种提取长江之歌伴奏MP3原版的方法,帮助大家轻松实现这一目标。一、使用音频编辑软件提取伴奏Audacity是一款免费且开源的音频编辑器,适用于Windows、Mac和Linux系统。它拥有强大的功能,包括多轨编辑、降噪、混音、添加效果等。
561
2025-04-02 11:08
 苹果手机录音怎么去除杂音?从环境优化到后期降噪
苹果手机录音怎么去除杂音?从环境优化到后期降噪
在使用苹果手机进行录音时,遇到杂音问题是一个常见的困扰。杂音可能来源于外部环境、设备硬件、软件设置等多个方面。苹果手机录音怎么去除杂音?本文将介绍一些实用的方法,帮助你去除苹果手机录音中的杂音,提升录音质量。一、优化录音环境选择安静环境:录音时,尽量选择一个安静、没有回声或混响的环境。避免在嘈杂的户外或开放空间录音,以减少背景噪音的干扰。减少声音反射:如果可能的话,可以在录音环境中放置一些吸音材料
2212
2025-03-31 13:37
 电脑提取视频中的音频要怎么做?新手教程来了
电脑提取视频中的音频要怎么做?新手教程来了
在数字化时代,视频内容已成为信息传播的重要载体,而其中的音频部分往往也蕴含着丰富的价值。无论是为了制作播客、提取背景音乐,还是进行语言学习,从视频中分离出高质量音频的需求日益增长。电脑提取视频中的音频要怎么做?本文将详细介绍如何在电脑上轻松完成这一任务,无需专业背景,只需几步操作即可实现。一、选择合适的工具Audacity:作为一款开源的音频编辑软件,Audacity以其简洁的界面和强大的功能赢得
670
2025-03-26 10:34
 音频提取人声分离技术:原理与具体实践
音频提取人声分离技术:原理与具体实践
在数字化音频处理领域,人声分离是一项旨在从混合音频中提取人声或伴奏的技术。无论是音乐制作、影视后期还是语音识别预处理,这一技术都能显著提升音频处理的灵活性与效率。本文将系统梳理音频提取人声分离技术的核心方法。一、传统信号处理方法:基于物理特性的分离策略在传统音频工程中,人声分离主要依赖声学特征与统计模型的结合,典型方法包括:1、频谱减法(Spectral Subtraction)通过估计背景噪声的
1397
2025-03-17 09:35