




在短视频创作、音乐翻唱或影视剪辑场景中,提取视频中的纯净伴奏或人声是常见需求。如何只提取视频中的声音?传统方法需借助专业音频软件,但易我人声分离在线工具凭借AI技术,将这一复杂操作简化为“上传-处理-下载”三步,即使无音频编辑经验的用户也能快速掌握。
一、技术原理:AI驱动的智能音轨分离
易我人声分离采用深度学习算法,通过分析音频频谱特征,自动识别并分离人声与伴奏。其核心优势在于:
多音轨支持:可处理包含人声、乐器、环境音的复杂音频,分离出纯伴奏、纯人声及分轨乐器。
高精度输出:通过持续优化的神经网络模型,减少分离过程中的音质损失,保留原始音频的动态范围。
实时处理能力:依托云端算力,5分钟内的视频音频处理仅需数秒,长音频(如30分钟)处理时间控制在3分钟内。
二、操作流程:如何只提取视频中的声音
步骤1.访问并登录易我人声分离官网页面,选择“人声分离”功能。
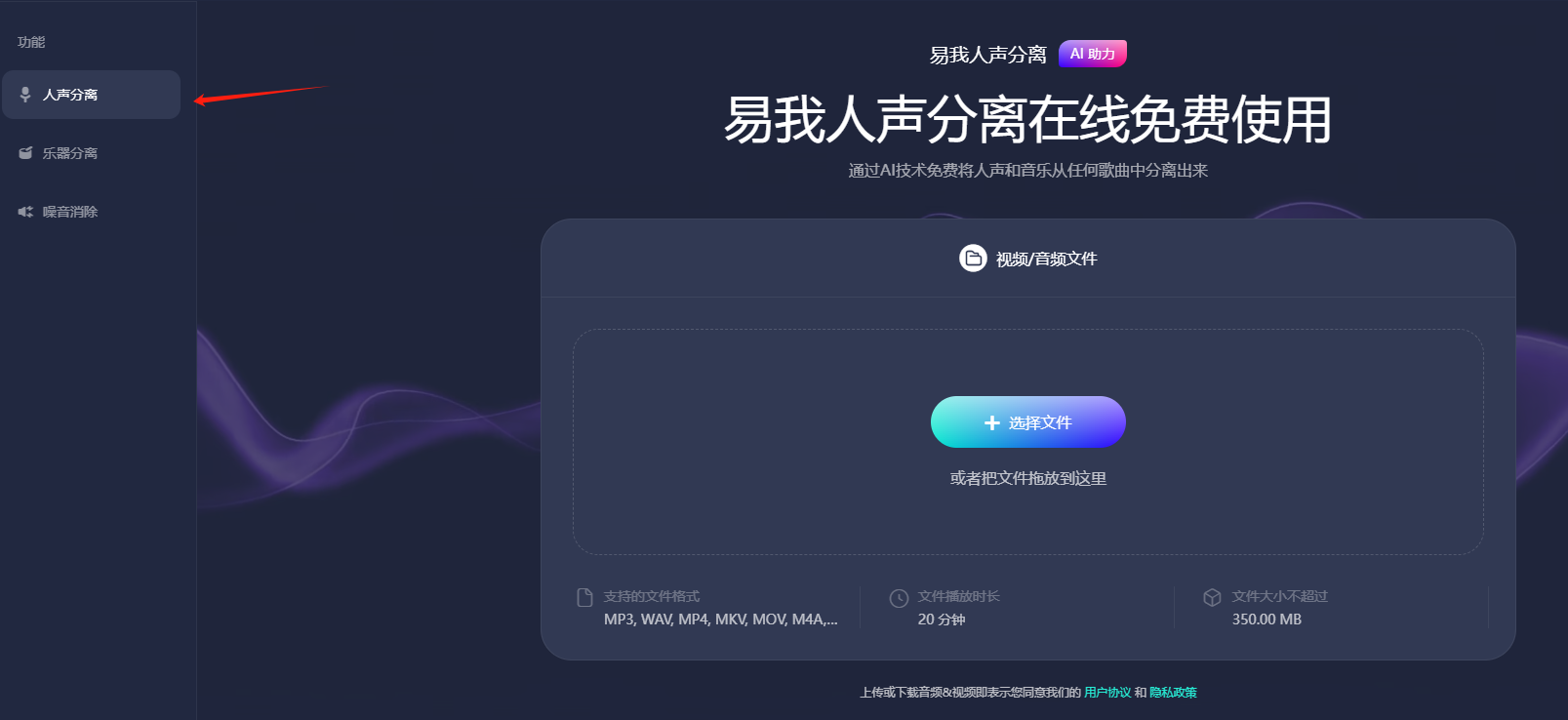
步骤2.点击“选择文件”,把音频或者视频文件上传到网页窗口中(或者直接拖拽文件到窗口中),等待AI处理。


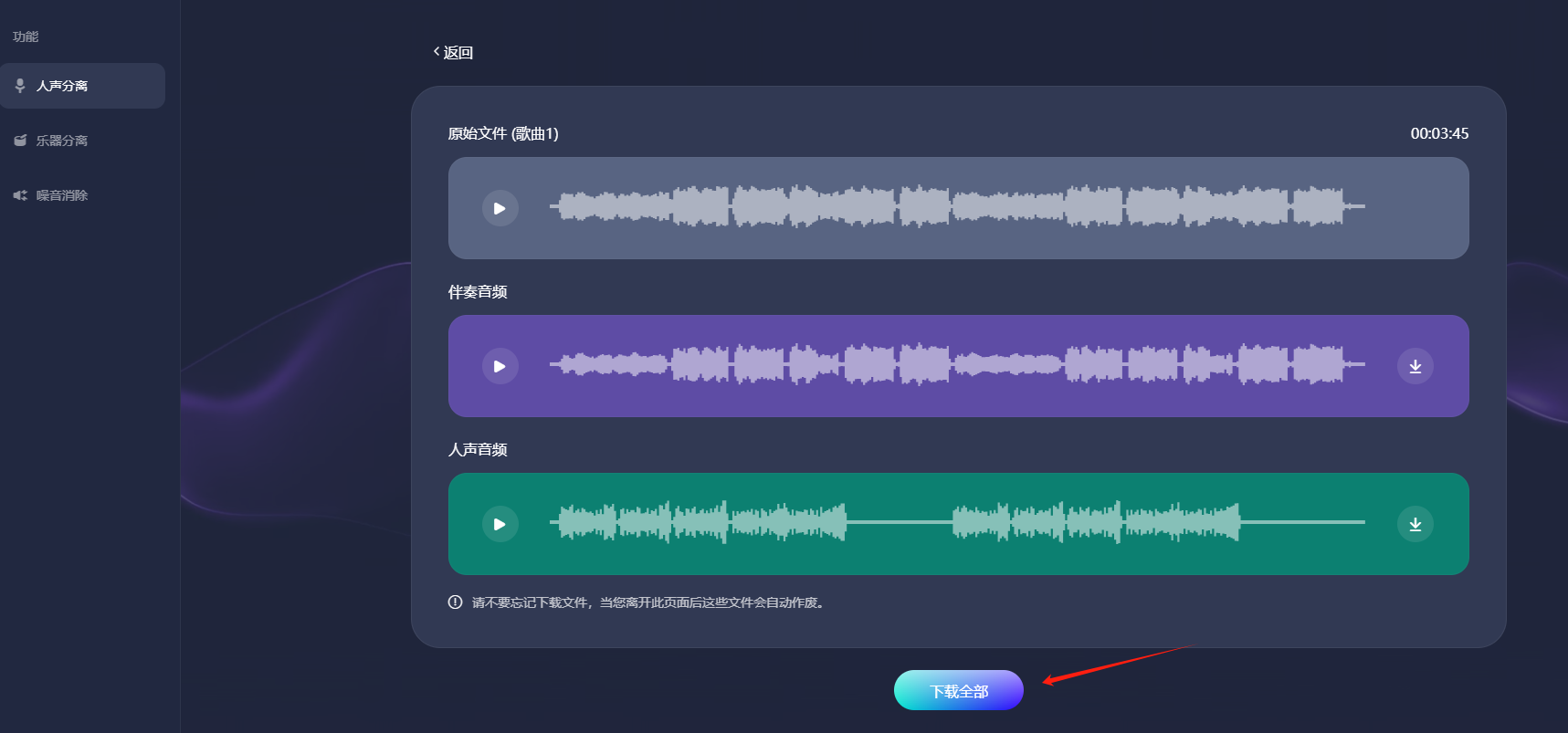
步骤3.AI处理完成后,会生成伴奏音频和人声音频,点击“下载全部”即可把音频下载到您的电脑上。
注意:请不要忘记下载文件,当您离开此页面后这些文件会自动作废。
三、应用场景与注意事项
典型使用场景
音乐创作:提取影视原声伴奏进行二次编曲,或分离人声制作阿卡贝拉。
语言学习:从外语视频中提取纯人声,用于听力训练或发音模仿。
版权处理:分离背景音乐后替换为合法授权的音频,规避侵权风险。
操作注意事项
文件兼容性:支持主流视频格式。
音质限制:在线工具采用有损压缩,对音质要求极高(如母带级音频)的用户建议使用桌面版软件。
版权合规:分离后的音频仅限个人学习、研究使用,商业用途需获得原作者授权。
四、进阶技巧:提升分离质量的操作建议
预处理优化:上传前用视频剪辑软件裁剪无关片段,减少AI处理数据量。
后处理调整:下载后用Audacity等工具微调音量平衡(如提升伴奏低音)。
总结
如何只提取视频中的声音?综上所述,易我人声分离在线工具通过AI技术降低了音频处理的门槛,使普通用户也能高效完成音轨分离任务。无论是创作灵感激发,还是版权合规处理,这一工具都提供了便捷的解决方案。未来,随着算法的持续迭代,其分离精度与处理速度还将进一步提升,成为数字内容创作者的得力助手。

 怎样提取视频里的音乐变成MP3?无需软件,轻点鼠标即可实现!
怎样提取视频里的音乐变成MP3?无需软件,轻点鼠标即可实现!

 录的音频怎么去除杂音?AI降噪无损人声音质
录的音频怎么去除杂音?AI降噪无损人声音质
 音频如何去除杂音?AI降噪,你值得拥有
音频如何去除杂音?AI降噪,你值得拥有
 录音的杂音怎么处理?一键消除噪音的新方案!
歌声与微笑伴奏MP3如何一键提取?分离伴奏的简单方法分享
录音的杂音怎么处理?一键消除噪音的新方案!
歌声与微笑伴奏MP3如何一键提取?分离伴奏的简单方法分享
 如何免费提取不白活一回伴奏?简单技巧公开!
如何免费提取不白活一回伴奏?简单技巧公开!
 怎么把视频中的音频提取成MP3?这个一键分离音频的方法一定要试!
怎么去掉录音里的杂音只保留人声?一键去除录音杂音的技巧
怎么把视频中的音频提取成MP3?这个一键分离音频的方法一定要试!
怎么去掉录音里的杂音只保留人声?一键去除录音杂音的技巧
 视频里的音频怎么提取?易我人声分离三步实现高效分离
视频里的音频怎么提取?易我人声分离三步实现高效分离
 录音怎么去杂音?易我人声分离一键降噪
音频背景杂音消除新利器:易我人声分离的智能降噪实践
录音怎么去杂音?易我人声分离一键降噪
音频背景杂音消除新利器:易我人声分离的智能降噪实践
 怎样消除噪音?一键消除音频噪音的新手教程
怎样消除噪音?一键消除音频噪音的新手教程