




易我人声分离
在短视频创作、播客录制、在线教育等场景中,音频质量直接影响内容传播效果。然而,交通噪音、电流声、键盘敲击声等背景杂音常成为困扰创作者的难题。在音频背景杂音消除的实践中,传统降噪工具或需复杂参数调试,或依赖专业设备,而基于AI技术的易我人声分离工具,正以"一键式智能降噪"重新定义音频处理流程。
一、传统降噪技术的痛点与AI破局
传统音频降噪依赖频谱减法、自适应滤波等技术,需手动选取噪音样本并调整阈值参数。以Adobe Audition为例,用户需先录制环境噪音样本,再通过"降噪/恢复"模块生成噪声轮廓,最后应用到整个音频文件。这一过程不仅耗时,且对操作者经验要求较高,稍有不慎便会导致人声失真或背景残留。
AI技术的引入彻底改变了这一局面。易我人声分离采用深度学习算法,通过海量音频数据训练出智能噪声识别模型。该模型可自动区分人声频段与环境噪音特征,无需人工干预即可完成降噪处理。
二、易我人声分离的实操案例
音频背景杂音消除可按照下面的三个步骤快速完成:
步骤1.进入易我人声分离官网(www.aifuse.cn),点击【立即提取】。

步骤2.选择“噪音消除”,将需要处理的音视频文件上传至工具中并等待处理。

步骤3.处理完成后会生成“原始文件”、“人声音频”、“降噪音频”三个文件,用户可选择单独下载某一文件或全部进行下载。
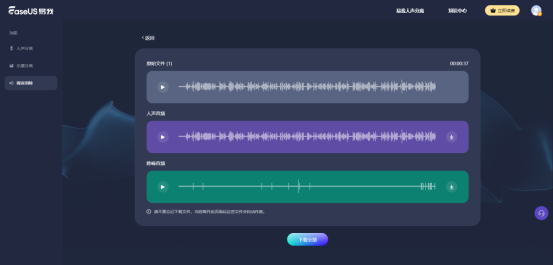
注意:当您离开此页面后这些文件会自动作废,请及时下载需要的文件。
三、总结
音频背景杂音消除的方法如上文所示。目前,易我人声分离已广泛应用于播客制作、会议纪要整理、影视后期等领域。随着AI技术的迭代,未来的音频降噪将向"零干预"方向发展。在内容创作爆发式增长的时代,易我人声分离这类AI工具正在降低音频处理的技术门槛。当创作者无需再为杂音困扰时,他们将能更专注于内容本身,这或许就是技术进步的真正价值所在。
猜你想看

 怎样消除噪音?一键消除音频噪音的新手教程
怎样消除噪音?一键消除音频噪音的新手教程
在视频创作、播客录制或音乐制作过程中,背景噪音常成为困扰创作者的“隐形敌人”——键盘敲击声、空调嗡鸣、电流杂音……这些不速之客不仅破坏音频质量,更可能让精心准备的内容大打折扣。怎样消除噪音?本文将以易我人声分离工具为核心,结合音频降噪领域的专业方法,为新手用户提供一套从原理到实操的完整解决方案,助您轻松实现“一键降噪”。一、噪音消除的科学原理:从信号处理到AI降噪音频降噪的本质是信号分离技术,即通

398
2025-09-01 11:19
 视频里的音乐怎么提取成音频?这几种方法超简单
视频里的音乐怎么提取成音频?这几种方法超简单
在刷视频时,你是否常被其中动听的音乐吸引,想将其提取出来单独欣赏或用于其他创作?今天,就来聊聊视频里的音乐怎么提取成音频。专业视频格式转换软件像易我视频转换器这类专业视频格式转换软件,是提取视频音乐的好帮手。使用时,先安装并打开软件,在主界面找到“音频提取”功能;接着点击“添加文件”,导入要提取音乐的视频;然后在输出格式中选好所需音频格式,如MP3、WAV等;最后点击“开始提取”,软件就会把视频中
494
2025-08-28 12:47
如何将录屏的声音提取出来?教你一招提取声音的偷懒方法!
在日常工作或娱乐中,我们经常需要从录屏文件中提取清晰的人声或背景音乐。例如,制作教学视频时需要去除背景噪音,或为K歌准备原版伴奏。如何将录屏的声音提取出来?传统方法需要专业音频软件,操作复杂且耗时。本文将介绍一款超级方便的在线工具——易我人声分离,通过AI技术快速分离人声与背景音乐,无需下载安装,三步即可完成操作。一、易我人声分离的三步分离法易我人声分离是一款功能强大且操作便捷的在线 AI 音频编
499
2025-08-20 10:19
 怎么去掉视频的BGM,留下干净的人声音频?
怎么去掉视频的BGM,留下干净的人声音频?
在短视频创作、翻唱改编或字幕制作等场景中,怎么去掉视频的BGM、提取干净的人声是许多创作者的痛点。传统方法需要复杂的音频编辑软件和专业技能,而易我人声分离工具通过AI技术实现了一键式操作,让非专业用户也能快速完成人声与背景音乐的分离。本文将详细介绍这款工具的操作流程及核心优势。一、为什么选择易我人声分离工具?易我人声分离是一款基于深度学习算法开发的音频处理工具,其核心功能包括:智能分离技术:通过A
612
2025-08-14 14:33
 如何提取课件中的音频?纯净人声的完整提取指南
如何提取课件中的音频?纯净人声的完整提取指南
在教学中,教师常需从PPT课件、教学视频中提取音频素材进行二次创作,如制作听力练习、语音分析或字幕校对。然而,直接提取的音频往往包含背景音乐、环境音效等干扰元素,如何提取课件中的音频成为关键需求。本文将结合课件音频提取与人声分离技术,提供一套从课件到纯净人声的完整解决方案。提取方法一:PPT文件解压法(适用于.pptx格式)PPT课件的音频文件通常嵌入在媒体文件夹中,通过修改文件扩展名可快速提取:
412
2025-08-11 09:33
 如何提取歌曲沂蒙颂伴奏?易我人声分离在线工具使用指南
如何提取歌曲沂蒙颂伴奏?易我人声分离在线工具使用指南
经典红色歌曲《沂蒙颂》以悠扬的旋律和深情的歌词传唱数十年,无论是翻唱表演、音乐创作还是教学演示,纯净的伴奏版本都是不可或缺的核心素材。然而,官方伴奏资源稀缺、版权限制严格等问题常让爱好者陷入困境。本文将结合易我人声分离工具的AI技术,详细解析如何通过在线操作快速提取歌曲沂蒙颂伴奏,并梳理版权合规与使用注意事项。一、技术原理:AI如何分离人声与伴奏传统音频分离依赖频谱分析、相位抵消等技术,需手动调整
448
2025-08-07 09:33
 为了谁歌曲伴奏的提取教程,三步就会,小白福音
为了谁歌曲伴奏的提取教程,三步就会,小白福音
在翻唱经典歌曲《为了谁》时,许多音乐爱好者常因找不到纯净伴奏而困扰。提取《为了谁》歌曲伴奏的传统方法依赖专业音频软件进行频谱分析或相位抵消,不仅操作复杂,且对设备要求较高。易我人声分离凭借其AI驱动的智能分离技术,将这一过程简化为“上传-处理-下载”三步,成为音乐创作、教学及K歌场景中的高效工具。一、技术内核:深度学习重构音频分离范式易我人声分离的核心技术基于多模态深度学习框架,通过训练超过100
432
2025-08-05 09:29
 从视频里怎么提取音频呢?这个在线工具一键搞定
从视频里怎么提取音频呢?这个在线工具一键搞定
在短视频创作、音乐翻唱或会议记录整理等场景中,从视频中提取纯净音频的需求日益增长。从视频里怎么提取音频呢?传统方法需下载专业软件、学习复杂操作,而基于AI技术的易我人声分离在线工具,凭借其“零门槛、高效率、多功能”的特点,成为普通用户的首选。本文将详细解析其技术原理、操作步骤及使用注意事项。一、技术特点:AI驱动的智能音频处理易我人声分离由易我科技研发,采用深度学习算法与神经网络模型,通过海量音频
659
2025-08-01 10:03
 怎样去除视频BGM,留下干净人声?
怎样去除视频BGM,留下干净人声?
在短视频创作、影视剪辑与音乐制作领域,背景音乐(BGM)与原始人声的分离需求日益增长。传统方法依赖专业音频工程师手动操作,耗时且成本高昂。怎样去除视频BGM?易我人声分离作为新一代AI音频处理工具,通过深度学习算法实现了一键式智能分离,为普通用户提供了高效解决方案。本文将系统解析其技术原理、操作流程及注意事项。一、技术原理:深度学习驱动的智能分离易我人声分离的核心技术基于卷积神经网络(CNN)与循
661
2025-07-30 09:44
 视频配乐怎么提取?AI技术让伴奏提取更简单
视频配乐怎么提取?AI技术让伴奏提取更简单
在短视频创作、K歌翻唱或音乐制作中,提取视频中的纯净伴奏一直是用户的核心需求。视频配乐怎么提取?传统方法依赖专业软件,操作复杂且效果不稳定,而非专业用户往往望而却步。如今,基于AI技术的易我人声分离工具,以“一键式”操作和高保真分离效果,重新定义了视频配乐提取的标准。本文将从技术原理、操作流程、应用场景三个维度,全面解析这款工具如何成为用户的首选。一、技术突破:AI如何实现人声与伴奏的精准分离?易
583
2025-07-28 09:22
 霸王别姬伴奏完整版的制作提取方法,简单三步即可完成
霸王别姬伴奏完整版的制作提取方法,简单三步即可完成
在华语乐坛的经典作品中,屠洪刚演唱的《霸王别姬》以其激昂的旋律与史诗般的叙事,成为跨越时代的文化符号。当创作者需要为翻唱、舞蹈编排或影视配乐提取纯净伴奏时,传统方法常因音质损耗或操作复杂而受限。如今,基于AI算法的易我人声分离技术,正以毫秒级处理速度与高保真分离效果,重新定义音乐伴奏提取的标准。本文就将介绍霸王别姬伴奏完整版的制作提取方法。一、技术突破:从相位抵消到深度学习传统伴奏提取依赖“中置声
418
2025-07-23 09:19
 爱情买卖伴奏怎么提取?新手在家自制伴奏教程
爱情买卖伴奏怎么提取?新手在家自制伴奏教程
在短视频创作、K歌翻唱或音乐制作场景中,获取高质量的伴奏是关键环节。以经典歌曲《爱情买卖》为例,通过易我人声分离这一AI驱动的在线工具,用户无需复杂操作即可快速提取纯净伴奏。本文将结合技术原理与实操步骤,为您呈现完整的爱情买卖伴奏提取的解决方案。一、技术原理:AI如何实现人声与伴奏分离易我人声分离基于深度学习框架,采用多尺度特征融合网络进行音频解混。该技术通过以下步骤实现:频谱分析:将音频信号转换
438
2025-07-21 08:48